
In short
- Retries help, but they're only one piece of webhook reliability.
- A solid setup combines retries, idempotency, dead-letter queues, replay tooling, and observability.
- Missing any one of those turns a small hiccup into a slow, expensive incident.
Most teams wire up a retry loop and move on. That works fine in staging. In production, webhooks are a distributed systems problem, and retry loops alone don't cut it.
Retries are your first line of defense, not your only one
Retries handle the easy failures: a brief network glitch, a momentary 502 from a deployment rolling out, a DNS hiccup that resolves in seconds. They buy your system time.
What they don't handle is the aftermath. Every retried event is a potential duplicate. Every retry storm is a potential traffic spike that makes the original problem worse. And if the receiving service is genuinely down for an hour, retries alone just queue up pressure.
Think of retries as a shock absorber. They smooth out bumps. They don't fix the road.

Set retry boundaries before you need them
The worst time to figure out your retry policy is during an incident. Set clear rules up front so behavior stays predictable under pressure.
What to retry:
- Timeouts (the endpoint didn't respond in time)
- 5xx errors (the server hit an internal problem)
- 429 responses (rate-limited, worth trying again later)
What not to retry:
- Most 4xx errors. A 400 Bad Request won't magically fix itself on the next attempt. Something needs to change in the payload or configuration first.
How to space retries: Use exponential backoff with full jitter. A practical schedule looks like this: 1 second, 5 seconds, 25 seconds, 2 minutes, 10 minutes, 30 minutes.
Without jitter, every failed request retries at the exact same moment. That synchronizes load and can turn a small outage into a big one. Jitter spreads retries across time so recovery happens gradually.

Set hard limits: Cap both the number of attempts (say, 6) and the total retry window (say, 24 hours). Whichever limit hits first, stop retrying and route the event to your dead-letter queue.
Idempotency keeps duplicates harmless
At-least-once delivery means duplicates are a normal part of the system. They're not a bug. They're a design tradeoff you need to handle explicitly.
The fix is idempotency: making sure that processing the same event twice produces the same result as processing it once. Your consumer checks whether it's already handled this event, and if so, skips the work.
You need a stable event ID (from the provider or generated deterministically) and a place to store which IDs you've already processed. A simple database table with a unique constraint works well. Set a TTL on records so your storage doesn't grow forever.
For billing events, keep those dedupe records longer. A duplicate charge three weeks later is worse than a slightly larger database table. For low-risk notifications, 24 to 72 hours is usually plenty.
For a deeper dive, check out the idempotency checklist.
Dead-letter queues turn failures into recoverable work
After your retries are exhausted, the event needs somewhere to go. That's your dead-letter queue (DLQ).
A good DLQ stores enough context to replay safely later: the original payload, headers, attempt history, and the last error message. Without that context, recovering from the DLQ becomes a guessing game.
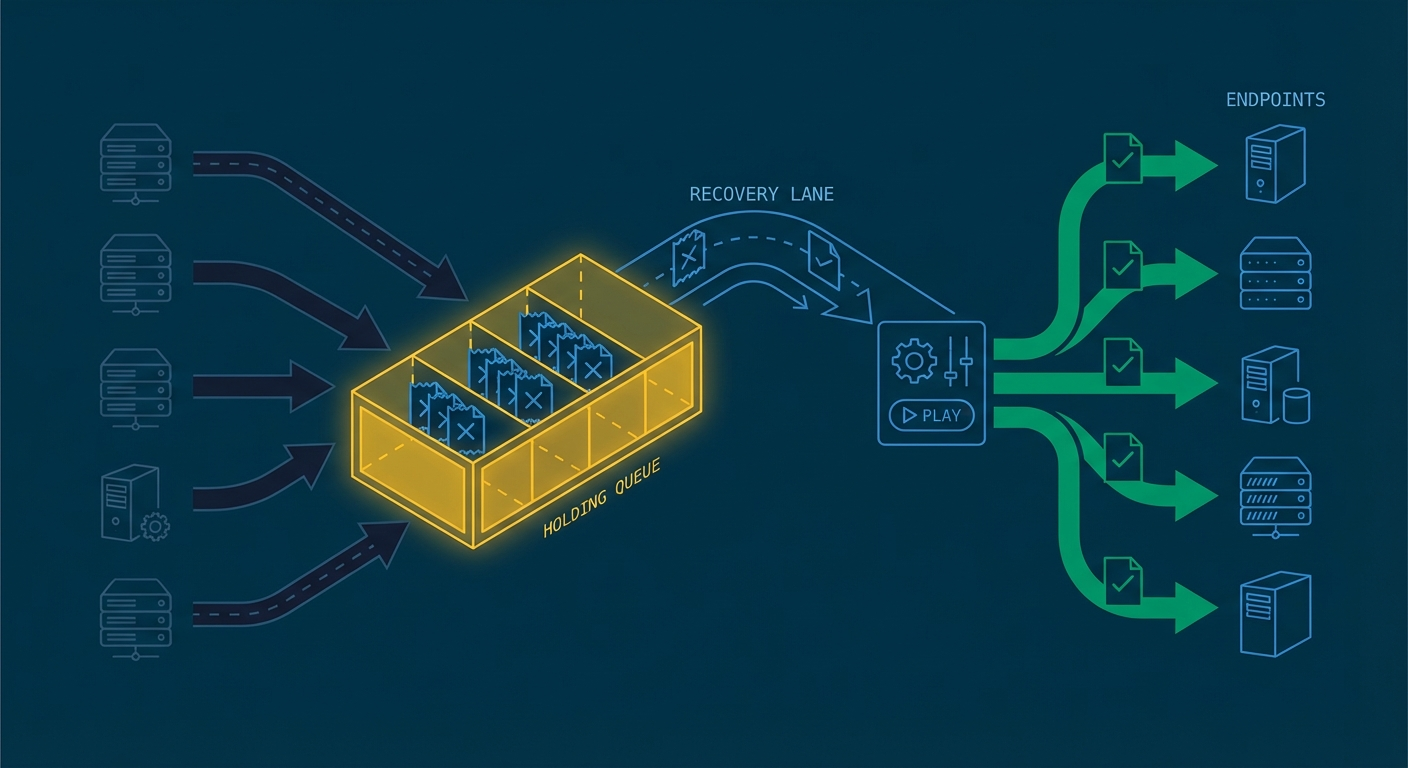
The key mindset shift: a DLQ is a recovery lane, not a graveyard. Events in the DLQ should be visible, searchable, and replayable. If your team treats the DLQ as "stuff that failed and we'll look at it someday," you'll accumulate a backlog that nobody wants to touch.
Replay tooling closes the loop
Replays let you reprocess events after fixing the root cause. They're what makes DLQs useful instead of just storage.
Build two replay modes:
- Single event replay for surgical fixes ("this one payment webhook failed, replay it after we patched the handler")
- Filtered batch replay for closing out incidents ("replay all order.created events from the last 6 hours that hit a 503")
Add a dry-run option for batch replays. Running 10,000 replays without checking the result first is how you create a second incident while recovering from the first one.
Observability gives you early warning
Good metrics tell you when reliability is drifting before customers notice. This is where teams usually get the most leverage for the least effort.
Track these five signals:
- Success rate: percentage of events delivered on first attempt
- Retry depth: how many attempts events need before succeeding (or exhausting)
- Oldest undelivered event: how far behind is the system?
- DLQ backlog size: is it growing or stable?
- Duplicate detection count: are duplicates trending up?
Alert on trends, not just hard failures. A slowly rising retry depth often shows up hours before a visible outage. That's your window to investigate and fix things before anyone notices.
For a full monitoring setup, see the webhook monitoring checklist.
Patterns that look fine in staging and break in production
A few common traps worth calling out:
- Immediate retry loops. Retrying instantly after a failure just hammers the endpoint harder. Always wait before the first retry.
- Infinite retries. Without a cap, a permanently failing endpoint generates traffic forever. Set a max.
- Retrying all 4xx errors. A 401 Unauthorized won't fix itself on retry. Neither will a 404. Reserve retries for transient failures.
- Shipping without idempotency. "We'll add it later" is how duplicate charges happen. Add it from the start for anything that touches money or user state.
- No replay tooling. When an incident resolves, you need a way to reprocess the events that failed. Without replay, recovery is manual, slow, and error-prone.
Your Monday morning checklist
If you're starting from scratch, work through this in order. Each step builds on the previous one.
- Define which status codes are retryable
- Implement exponential backoff
- Add full jitter to retry intervals
- Set max attempts and max retry window
- Add idempotency key handling at the consumer
- Store dedupe records with a TTL
- Route exhausted events to a DLQ
- Build replay tooling for single and batch recovery
- Instrument success rate, retry depth, and DLQ metrics
- Run one failure simulation to verify the whole chain
{
"eventId": "evt_123",
"status": "queued",
"attempt": 1,
"maxAttempts": 6
}Where Hookwing fits
Hookwing handles retries, dead-letter queues, and replay out of the box. Exponential backoff with jitter is the default. Exhausted events route to a visible DLQ. Replay is one click for a single event, or a filtered batch for incident recovery.
The goal: make failure handling boring. Clear retry behavior, safe deduplication, visible queues, fast replay.
Ready to ship with confidence?
Start with retry boundaries and idempotency this week. Then add DLQ and replay. That sequence gives the fastest reduction in incident pain with the least upfront effort.